三、Agent的四大组成部分详解
12/20/2025
Agent
1. 组成部分总览
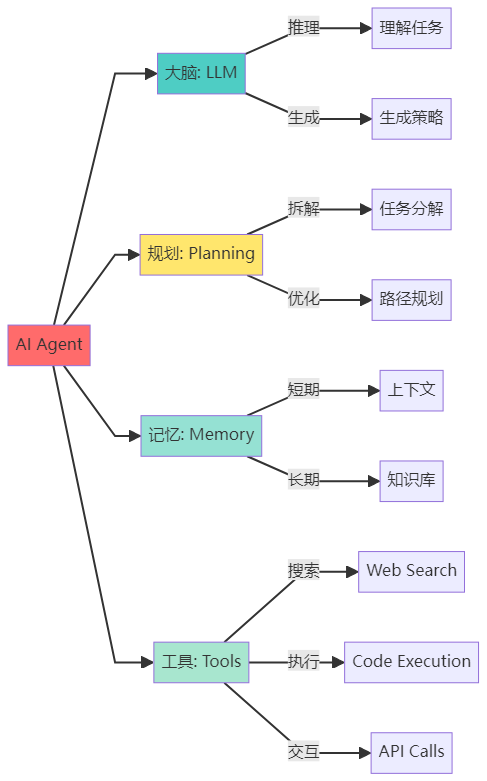
2. 组成部分一:大语言模型(LLM Brain)
作用与地位
LLM是Agent的「大脑」,负责:
- 理解用户意图
- 生成推理过程
- 决策选择工具
- 综合信息输出
当前主流选择
| 模型 | 优势 | 场景 | 成本 |
|---|---|---|---|
| GPT-5/Claude | 强大推理能力 | 负责任务、高精度 | 高 |
| DeepSeek-R1 | 性价比高、推理能力强 | 企业级部署 | 低 |
| Gemini2.0 | 多模态、Agent优化 | 需要视觉理解 | 中 |
实际代码示例
1from langchain_openai import ChatOpenAI
2
3# 初始化LLM作为Agent的大脑
4llm = ChatOpenAI(
5 model="gpt-4",
6 temperature=0, # 降低随机性,提高推理稳定性
7)
8
9# LLM的推理能力展示
10response = llm.invoke(
11 "你需要查找2024年奥运会金牌榜,然后比较中美两国的金牌数。请分步思考如何完成这个任务。"
12)
13print(response.content)
14
15# 输出示例:
16# 思考步骤:
17# 1. 首先需要调用搜索工具查找"2024奥运会金牌榜"
18# 2. 从搜索结果中提取中国和美国的金牌数
19# 3. 进行数值比较
20# 4. 生成比较结果关键点:
temperature=0:让Agent在推理时更稳定、更可预测- 提示词需要引导「分步思考」,这是CoT(Chain of Thought)的核心
3.组成部分二:规划模块(Planning)
为什么需要规划?
举个例子:如果任务是「帮我准备一场技术分享会」,没有规划的Agent会:
- 不知道从哪开始
- 可能遗漏重要步骤
- 浪费大量token重复思考
有规划的Agent会:
1确定主题和目标听众
2搜索相关技术资料
3设计PPT大纲
4准备演示Demo
5生成演讲稿两种主流规划方法
方法一:ReAct框架(边想边做)

ReAct特点:
- ✅ 灵活:可以根据中间结果调整计划
- ✅ 适合探索性任务
- ❌ Token消耗大:每一步都要调用LLM
方法二:Plan-and-Execute(先计划后执行)
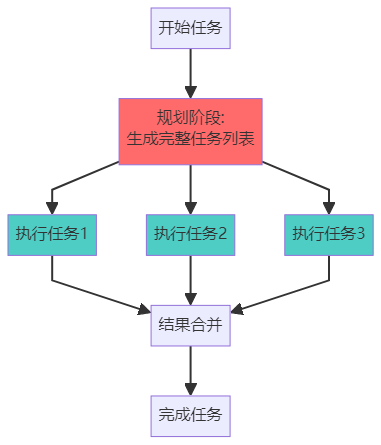
Plan-and-Execute特点:
- ✅ 高效:只需调用一次LLM规划
- ✅ 可并行执行多个任务
- ❌ 不灵活:难以根据中间结果调整
实际代码对比
ReAct实现
1from langchain.agents import create_react_agent, AgentExecutor
2from langchain.tools import Tool
3
4# 定义工具
5search_tool = Tool(
6 name="Search",
7 func=search_function,
8 description="搜索互联网信息"
9)
10
11# 创建ReAct Agent
12agent = create_react_agent(llm, [search_tool])
13agent_executor = AgentExecutor(agent=agent, tools=[search_tool], verbose=True)
14
15# 执行任务
16result = agent_executor.invoke({
17 "input": "找出DeepSeek-R1的训练成本,并与GPT-4对比"
18})
19
20# 输出过程(verbose=True会显示):
21# Thought: 我需要搜索DeepSeek-R1的信息
22# Action: Search("DeepSeek-R1 training cost")
23# Observation: [搜索结果]
24# Thought: 接下来需要搜索GPT-4的成本
25# Action: Search("GPT-4 training cost")
26# Observation: [搜索结果]
27# Thought: 现在可以进行对比了
28# Final Answer: [对比结果]Plan-and-Execute实现:
1from langchain.agents import Plan, Execute
2
3# 第一步:规划
4planner = create_planner(llm)
5plan = planner.plan("分析2024年AI Agent市场趋势")
6
7# 输出的计划:
8# Task 1: 搜索2024年AI Agent市场报告
9# Task 2: 提取市场规模数据
10# Task 3: 识别主要参与者
11# Task 4: 总结趋势和预测
12
13# 第二步:执行
14executor = create_executor(tools)
15results = executor.execute(plan) # 按计划依次执行选择建议
- 探索性任务(不知道中间会遇到什么)→ 用ReAct
- 流程明确的任务(步骤固定)→ 用Plan-and-Execute
- 复杂混合任务 → 两者结合
4.组成部分三:记忆模块(Memory)
为什么记忆很重要?
想象你在和一个朋友聊天:
- 没有记忆:每次对话都是新的,对方完全不记得你之前说过什么
- 有记忆:对方记得你的喜好、之前的讨论,对话更流畅
Agent也一样。记忆分为两类:
短期记忆(Short-term Memory)
作用:保存当前任务的上下文存储内容:
- 当前对话历史
- 中间步骤的结果
- 临时变量和状态
技术实现:
1from langchain.memory import ConversationBufferMemory
2
3# 创建对话记忆
4memory = ConversationBufferMemory(
5 memory_key="chat_history",
6 return_messages=True
7)
8
9# Agent执行时自动记录
10agent_executor = AgentExecutor(
11 agent=agent,
12 tools=tools,
13 memory=memory, # 添加记忆
14 verbose=True
15)
16
17# 第一轮对话
18agent_executor.invoke({"input": "我叫张三,在北京工作"})
19
20# 第二轮对话(Agent会记得上下文)
21agent_executor.invoke({"input": "帮我推荐北京的餐厅"})
22# Agent会知道你在北京,直接推荐北京的餐厅短期记忆的挑战:
- 📊 Token限制:GPT-4有128K token限制,长对话会超出
- 💰 成本问题:每次调用都要把整个历史发送给LLM
解决方案:
1from langchain.memory import ConversationSummaryMemory
2
3# 使用摘要记忆:自动总结历史对话
4summary_memory = ConversationSummaryMemory(
5 llm=llm,
6 max_token_limit=2000 # 超过限制时自动总结
7)
8
9# 效果:
10# 原始历史(5000 tokens)→ 总结后(500 tokens)
11# "用户是张三,在北京工作,偏好川菜,预算500元以内"长期记忆(Long-term Memory)
作用:存储可复用的知识和经验存储内容:
- 用户的个人信息和偏好
- 历史任务的成功经验
- 领域知识库
- 工具使用的最佳实践
技术实现:使用向量数据库
1from langchain.vectorstores import Chroma
2from langchain.embeddings import OpenAIEmbeddings
3
4# 1. 创建向量数据库(长期记忆)
5embeddings = OpenAIEmbeddings()
6vectorstore = Chroma(
7 collection_name="agent_memory",
8 embedding_function=embeddings
9)
10
11# 2. 存储经验
12vectorstore.add_texts([
13 "用户张三偏好川菜,预算500元",
14 "北京最佳川菜馆:川办、巴国布衣",
15 "搜索餐厅时应该考虑:位置、评分、价格、口味"
16])
17
18# 3. Agent执行任务时检索相关记忆
19query = "帮张三推荐餐厅"
20relevant_memories = vectorstore.similarity_search(query, k=3)
21
22# 4. 将记忆注入到prompt中
23prompt = f"""
24相关记忆:
25{relevant_memories}
26
27用户请求:{query}
28
29请根据记忆中的信息给出推荐。
30"""记忆架构图
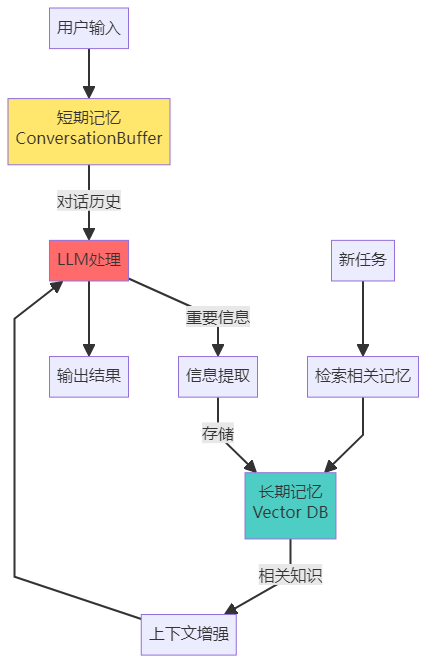
记忆模块的高级技巧
技巧1:自动清理不重要的记忆
1#基于重要性评分的记忆管理
2def should_store_in_long_term(message):
3 # 让LLM判断是否重要
4 importance = llm.predict(f"这条信息的重要性(1-10):{message}")
5 return int(importance) >= 7 # 只存储重要度>=7的信息技巧2:记忆的时效性管理
1#给记忆加上时间戳
2from datetime import datetime, timedelta
3
4memory_item = {
5 "content": "用户偏好川菜",
6 "timestamp": datetime.now(),
7 "expiry": datetime.now() + timedelta(days=30) # 30天后过期
8}
9
10# 检索时过滤过期记忆
11def get_valid_memories():
12 return [m for m in memories if m["expiry"] > datetime.now()]5.组成部分四:工具集(Tools)
工具是Agent的「超能力」
如果说LLM是Agent的大脑,那工具就是Agent的「手脚」和「超能力」。通过工具,Agent可以:
- 🔍 搜索互联网
- 💻 执行代码
- 📊 操作数据库
- 🔧 调用API
- 🖥️ 控制电脑
工具的定义与实现
一个工具的标准结构
1from langchain.tools import Tool
2
3def calculate(expression: str) -> str:
4 """执行数学计算"""
5 try:
6 result = eval(expression) # 实际生产中不要用eval
7 return f"计算结果:{result}"
8 except Exception as e:
9 return f"计算错误:{str(e)}"
10
11# 定义工具
12calculator_tool = Tool(
13 name="Calculator", # 工具名称(Agent会看到)
14 func=calculate, # 工具函数
15 description="""
16 用于数学计算。
17 输入:数学表达式字符串,如 "2 + 2" 或 "sqrt(16)"
18 输出:计算结果
19 何时使用:当需要进行精确数学计算时
20 """ # 描述很重要!Agent通过描述来决定是否使用该工具
21)关键要素:
- 清晰的名称:Agent通过名称快速识别工具
- 详细的描述:告诉Agent什么时候用、怎么用
- 标准的输入输出:保证工具能被正确调用
常用工具类型与实现
- 搜索工具
1from langchain.tools import DuckDuckGoSearchRun
2
3search = DuckDuckGoSearchRun()
4
5search_tool = Tool(
6 name="WebSearch",
7 func=search.run,
8 description="搜索互联网获取最新信息。适用于需要实时数据的场景。"
9)
10
11# 使用示例
12result = search.run("2024年诺贝尔物理学奖")2. 代码执行工具
1def python_executor(code: str) -> str:
2 """执行Python代码"""
3 import io
4 import sys
5 from contextlib import redirect_stdout
6
7 f = io.StringIO()
8 try:
9 with redirect_stdout(f):
10 exec(code)
11 return f.getvalue()
12 except Exception as e:
13 return f"错误:{str(e)}"
14
15code_tool = Tool(
16 name="PythonExecutor",
17 func=python_executor,
18 description="执行Python代码。适用于数据处理、计算、可视化等任务。"
19)
20
21# Agent可以这样用:
22# code_tool.run("""
23# import pandas as pd
24# data = [1, 2, 3, 4, 5]
25# print(f"平均值:{sum(data)/len(data)}")
26# """)3. API调用工具
1import requests
2
3def weather_api(city: str) -> str:
4 """查询天气"""
5 # 假设调用某个天气API
6 response = requests.get(f"https://api.weather.com/{city}")
7 return response.json()
8
9weather_tool = Tool(
10 name="WeatherAPI",
11 func=weather_api,
12 description="查询指定城市的天气信息。输入城市名,返回温度、湿度等信息。"
13)4. 数据库工具
1import sqlite3
2
3def query_database(sql: str) -> str:
4 """查询数据库"""
5 conn = sqlite3.connect('my_database.db')
6 cursor = conn.cursor()
7 try:
8 cursor.execute(sql)
9 results = cursor.fetchall()
10 return str(results)
11 except Exception as e:
12 return f"查询错误:{str(e)}"
13 finally:
14 conn.close()
15
16db_tool = Tool(
17 name="DatabaseQuery",
18 func=query_database,
19 description="执行SQL查询。适用于需要从数据库获取数据的场景。"
20)工具组合的实际案例
案例:构建一个数据分析Agent
1from langchain.agents import create_react_agent, AgentExecutor
2from langchain_openai import ChatOpenAI
3
4# 1. 准备工具集
5tools = [
6 search_tool, # 搜索数据
7 code_tool, # 数据处理
8 db_tool, # 数据库查询
9]
10
11# 2. 创建Agent
12llm = ChatOpenAI(model="gpt-4", temperature=0)
13agent = create_react_agent(llm, tools)
14agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
15
16# 3. 执行复杂任务
17result = agent_executor.invoke({
18 "input": """
19 帮我分析一下:
20 1. 从数据库中查询2024年的销售数据
21 2. 搜索行业平均增长率
22 3. 用Python计算我们的增长率
23 4. 对比并给出结论
24 """
25})
26
27# Agent的执行过程:
28# Thought: 需要先从数据库获取数据
29# Action: DatabaseQuery("SELECT * FROM sales WHERE year=2024")
30# Observation: [...数据...]
31#
32# Thought: 需要搜索行业数据
33# Action: WebSearch("2024年销售行业平均增长率")
34# Observation: [...行业数据...]
35#
36# Thought: 现在可以计算了
37# Action: PythonExecutor("
38# our_growth = (current - previous) / previous * 100
39# industry_avg = 15.2
40# print(f'我们的增长率:{our_growth}%,行业平均:{industry_avg}%')
41# ")
42# Observation: 我们的增长率:18.5%,行业平均:15.2%
43#
44# Thought: 可以给出结论了
45# Final Answer: [完整分析报告]工具使用的最佳实践
实践1:工具描述要精确
❌ 不好的描述:
1description="一个搜索工具"✅ 好的描述:
1description="""
2搜索互联网获取最新信息。
3- 输入:搜索关键词(字符串)
4- 输出:相关网页内容摘要
5- 适用场景:需要实时数据、最新新闻、当前事件
6- 不适用场景:历史数据、个人信息、数学计算
7"""实践2:工具要有错误处理
1def safe_tool(input_data):
2 try:
3 # 工具的实际逻辑
4 result = process(input_data)
5 return result
6 except Exception as e:
7 # 返回友好的错误信息,帮助Agent调整策略
8 return f"工具执行失败:{str(e)}。建议:尝试其他方法或简化输入。"实践3:工具要有使用日志
1import logging
2
3def logged_tool(input_data):
4 logging.info(f"工具被调用,输入:{input_data}")
5 result = execute(input_data)
6 logging.info(f"工具执行完成,输出:{result}")
7 return result